Workshop Datasets
Currently, most deepfake detection datasets focus primarily on binary classification labels and do not provide annotated masks for manipulated regions. This significantly limits the progress in deepfake localization tasks. To address this, we have constructed a large-scale deepfake detection and localization (DDL) dataset that includes both unimodal (image) and multimodal (audio-video) data, covering both visual and temporal task formats. Our dataset overcomes previous limitations related to coarse annotations of manipulated regions and a lack of diversity in manipulation techniques.
Dataset file metadata and data files, please visit the Dataset Files page.
Deepfake Detection and Localization Image (DDL-I) Dataset
View table 1 in detail1.5M+ Samples
Images with pixel-level annotations
61 Algorithms
Covering latest generation methods
Multi-Scenario
Single & multi-face contexts
Key Aspects
Diverse Forgery Scenarios
- The dataset covers both single-face and multi-face scenarios, simulating complex forgery content and contexts found in the real world.
Pixel-level Forgery Regions Annotations
- It provides detailed pixel-level forgery region mask labels that are preserved during the forgery process. These fine-grained annotations can advance the development of forgery localization tasks.
Comprehensive Deepfake Methods
- We integrated 61 deepfake methods across four major forgery types: face swapping, face reenactment, full-face synthesis, and face editing.
Training Data Description
In this task, we aim to detect deepfake images and localize deepfake areas with labels and masks access. The data consists of 1.2 million images, divided into three sub-datasets: "real", "fake", and "masks". The "real" sub-dataset contains genuine face images (label=0), while the "fake" sub-dataset holds artificially generated face images (label=1). Each image in the "fake" sub-dataset has a corresponding mask image located in the "masks" sub-dataset, which can be matched using the filename.
Sample Images

Figure 1: Examples of the DDL-I dataset. Real row represents the original image. Fake row contains the manipulated image. Mask row indicates the tampered region labels. Multi-Face Scenario refers to an image with multiple faces where one or more faces have been altered. Single-Face Scenario involves altering a local region within an image that contains only one face.
Table 1
Comparison of existing face deepfake datasets
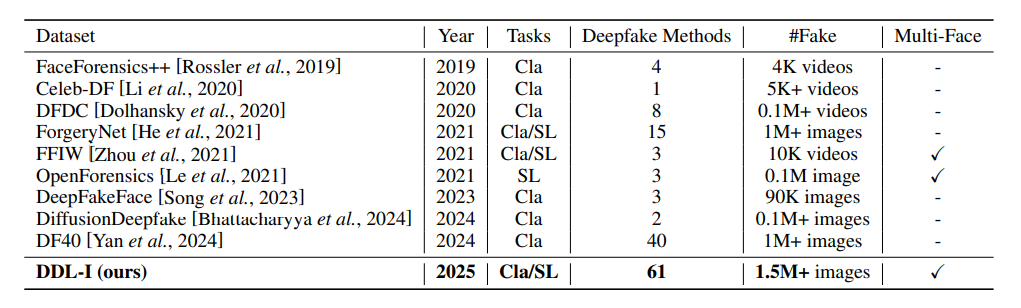
Our DDL-I surpasses others in terms of the diversity of forgery methods, the scale of
fake samples, and the complexity of forgery scenarios. Cla: Binary classification.
SL: Spatial forgery localization. Multi-Face: One or more faces in a multi-face image are manipulated.
Deepfake Detection and Localization Audio-Video (DDL-AV) Dataset
View table 2 in detailBy incorporating multiple forgery techniques and a large dataset, DDL-AV offers researchers a more challenging and practical dataset that better simulates complex forgery scenarios in the real world.
Advancing Audio Forgery Techniques
The dataset includes a suite of state-of-the-art audio forgery technologies, covering various text-to-speech, voice cloning, and voice swapping techniques. This significantly enhances the complexity of audio forgeries.
Comprehensive Visual Forgery Methods
For visual forgery, it integrates cutting-edge methods such as face swapping, facial animation, face attribute editing, and text-to-video generation (AIGC Video).
Diverse Forgery Modes
The dataset includes three forgery modes: fake audio and fake video, fake audio and real video, and real audio and fake video. Notably, it contains a substantial amount of data involving local manipulations with deletion, replacement, and insertion techniques.
Asynchronous Temporal Forgery Type
We innovatively introduce asynchronous temporal forgery types, where audio and video forgery segments occur on different time sequences.
Standardized Data Format
We standardized the data format to ensure compatibility and ease of use, setting it at 25fps frame rate, AAC audio encoding, H.264 video encoding, 224×224 resolution, and stereo audio
Training Data Description
In this task, we aim to detect the deepfake videos and temporal localize the fake segments in the videos with full-level labels access. The data consists of 0.2 million videos, divided into two sub-datasets: "real" and "fake." The "real" sub-dataset contains genuine audiovisual samples where both the audio and visual components are authentic.
The "fake" sub-dataset is further categorized into three types of forgeries:
- fake_audio_fake_visual: Here, both audio and visual components are artificially generated.
- fake_audio_real_visual: In this case, the audio component is artificially generated, while the visual component is genuine.
- real_audio_fake_visual: In this instance, the audio component is genuine, but the visual component is artificially generated.
For each fake video, we provide a corresponding JSON file recording the forged content in detail. Here is an example below.
Sample Images

Figure 2: Examples of the DDL-AV dataset. Green color represents real segments and red color represents fake content. Our innovation involves fabricating audio and video content at different time sequences.
Table 2
Details for publicly available audio-video deepfake datasets in chronological order
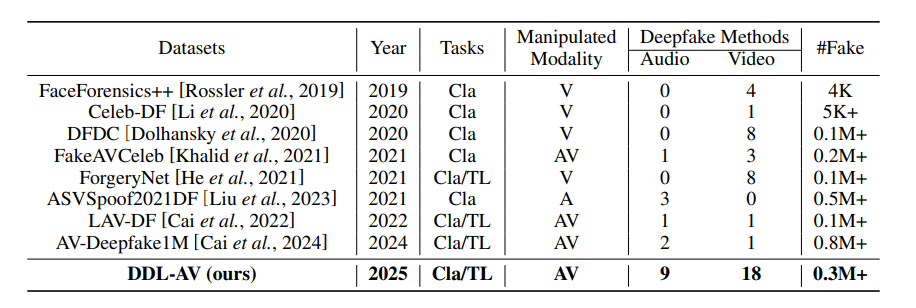
Cla: Binary classification, TL: Temporal localization, V: only video modality, A: only audio modality, AV: audio-video multiple modality.